An API implementation returns three X-RateLimit-* HTTP response headers to a requesting API client. What type of information do these response headers indicate to the API client?
A.
The error codes that result from throttling
B.
A correlation ID that should be sent in the next request
C.
The HTTP response size
D.
The remaining capacity allowed by the API implementation
The remaining capacity allowed by the API implementation
Explanation: Explanation
Correct Answer: The remaining capacity allowed by the API implementation.
*****************************************
>> Reference: https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-slabased-
policies#response-headers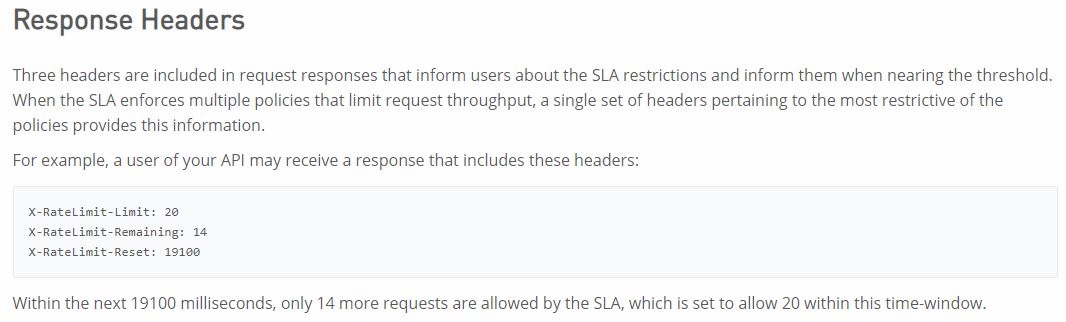
In an organization, the InfoSec team is investigating Anypoint Platform related data traffic. From where does most of the data available to Anypoint Platform for monitoring and alerting originate?
A.
From the Mule runtime or the API implementation, depending on the deployment model
B.
From various components of Anypoint Platform, such as the Shared Load Balancer, VPC, and Mule runtimes
C.
From the Mule runtime or the API Manager, depending on the type of data
D.
From the Mule runtime irrespective of the deployment model
From the Mule runtime irrespective of the deployment model
Explanation: Explanation
Correct Answer: From the Mule runtime irrespective of the deployment model
*****************************************
>> Monitoring and Alerting metrics are always originated from Mule Runtimes irrespective
of the deployment model.
>> It may seems that some metrics (Runtime Manager) are originated from Mule Runtime
and some are (API Invocations/ API Analytics) from API Manager. However, this is
realistically NOT TRUE. The reason is, API manager is just a management tool for API
instances but all policies upon applying on APIs eventually gets executed on Mule
Runtimes only (Either Embedded or API Proxy).
>> Similarly all API Implementations also run on Mule Runtimes.
So, most of the day required for monitoring and alerts are originated fron Mule Runtimes
only irrespective of whether the deployment model is MuleSoft-hosted or Customer-hosted
or Hybrid.
A retail company with thousands of stores has an API to receive data about purchases and
insert it into a single database. Each individual store sends a batch of purchase data to the
API about every 30 minutes. The API implementation uses a database bulk insert
command to submit all the purchase data to a database using a custom JDBC driver
provided by a data analytics solution provider. The API implementation is deployed to a
single CloudHub worker. The JDBC driver processes the data into a set of several
temporary disk files on the CloudHub worker, and then the data is sent to an analytics
engine using a proprietary protocol. This process usually takes less than a few minutes.
Sometimes a request fails. In this case, the logs show a message from the JDBC driver
indicating an out-of-file-space message. When the request is resubmitted, it is successful.
What is the best way to try to resolve this throughput issue?
A.
se a CloudHub autoscaling policy to add CloudHub workers
B.
Use a CloudHub autoscaling policy to increase the size of the CloudHub worker
C.
Increase the size of the CloudHub worker(s)
D.
Increase the number of CloudHub workers
Increase the number of CloudHub workers
Explanation: Explanation
Correct Answer: Increase the size of the CloudHub worker(s)
*****************************************
The key details that we can take out from the given scenario are:
>> API implementation uses a database bulk insert command to submit all the purchase
data to a database
>> JDBC driver processes the data into a set of several temporary disk files on the
CloudHub worker
>> Sometimes a request fails and the logs show a message indicating an out-of-file-space
message
Based on above details:
>> Both auto-scaling options does NOT help because we cannot set auto-scaling rules
based on error messages. Auto-scaling rules are kicked-off based on CPU/Memory usages
and not due to some given error or disk space issues.
>> Increasing the number of CloudHub workers also does NOT help here because the
reason for the failure is not due to performance aspects w.r.t CPU or Memory. It is due to
disk-space.
>> Moreover, the API is doing bulk insert to submit the received batch data. Which means,
all data is handled by ONE worker only at a time. So, the disk space issue should be
tackled on "per worker" basis. Having multiple workers does not help as the batch may still
fail on any worker when disk is out of space on that particular worker.
Therefore, the right way to deal this issue and resolve this is to increase the vCore size of
the worker so that a new worker with more disk space will be provisioned.
What Mule application deployment scenario requires using Anypoint Platform Private Cloud Edition or Anypoint Platform for Pivotal Cloud Foundry?
A.
When it Is required to make ALL applications highly available across multiple data centers
B.
When it is required that ALL APIs are private and NOT exposed to the public cloud
C.
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
D.
When ALL backend systems in the application network are deployed in the
organization's intranet
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
Explanation: Explanation
Correct Answer: When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data.
*****************************************
We need NOT require to use Anypoint Platform PCE or PCF for the below. So these
options are OUT.
>> We can make ALL applications highly available across multiple data centers using
CloudHub too.
>> We can use Anypoint VPN and tunneling from CloudHub to connect to ALL backend
systems in the application network that are deployed in the organization's intranet.
>> We can use Anypoint VPC and Firewall Rules to make ALL APIs private and NOT
exposed to the public cloud.
Only valid reason in the given options that requires to use Anypoint Platform PCE/ PCF is -
When regulatory requirements mandate on-premises processing of EVERY data item,
including meta-data
An API experiences a high rate of client requests (TPS) vwth small message paytoads.
How can usage limits be imposed on the API based on the type of client application?
A.
Use an SLA-based rate limiting policy and assign a client application to a matching SLA
tier based on its type
B.
Use a spike control policy that limits the number of requests for each client application
type
C.
Use a cross-origin resource sharing (CORS) policy to limit resource sharing between
client applications, configured by the client application type
D.
Use a rate limiting policy and a client ID enforcement policy, each configured by the
client application type
Use an SLA-based rate limiting policy and assign a client application to a matching SLA
tier based on its type
Explanation: Correct Answer: Use an SLA-based rate limiting policy and assign a client
application to a matching SLA tier based on its type.
*****************************************
>> SLA tiers will come into play whenever any limits to be imposed on APIs based on client
type
Reference: https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-slabased-
policies
The application network is recomposable: it is built for change because it "bends but does
not break"
A.
TRUE
B.
FALSE
TRUE
Explanation: *****************************************
>> Application Network is a disposable architecture.
>> Which means, it can be altered without disturbing entire architecture and its
components.
>> It bends as per requirements or design changes but does not break
Reference: https://www.mulesoft.com/resources/api/what-is-an-application-network
An API has been updated in Anypoint Exchange by its API producer from version 3.1.1 to
3.2.0 following accepted semantic versioning practices and the changes have been
communicated via the API's public portal.
The API endpoint does NOT change in the new version.
How should the developer of an API client respond to this change?
A.
The update should be identified as a project risk and full regression testing of the functionality that uses this API should be run
B.
The API producer should be contacted to understand the change to existing functionality
C.
The API producer should be requested to run the old version in parallel with the new one
D.
The API client code ONLY needs to be changed if it needs to take advantage of new
features
The API client code ONLY needs to be changed if it needs to take advantage of new
features
Reference: https://docs.mulesoft.com/exchange/to-change-raml-version
What is true about the technology architecture of Anypoint VPCs?
A.
The private IP address range of an Anypoint VPC is automatically chosen by CloudHub
B.
Traffic between Mule applications deployed to an Anypoint VPC and on-premises
systems can stay within a private network
C.
Each CloudHub environment requires a separate Anypoint VPC
D.
VPC peering can be used to link the underlying AWS VPC to an on-premises (non
AWS) private network
Traffic between Mule applications deployed to an Anypoint VPC and on-premises
systems can stay within a private network
Explanation: Explanation
Correct Answer: Traffic between Mule applications deployed to an Anypoint VPC and onpremises
systems can stay within a private network
*****************************************
>> The private IP address range of an Anypoint VPC is NOT automatically chosen by
CloudHub. It is chosen by us at the time of creating VPC using thr CIDR blocks.
CIDR Block: The size of the Anypoint VPC in Classless Inter-Domain Routing (CIDR)
notation.
For example, if you set it to 10.111.0.0/24, the Anypoint VPC is granted 256 IP addresses
from 10.111.0.0 to 10.111.0.255.
Ideally, the CIDR Blocks you choose for the Anypoint VPC come from a private IP space,
and should not overlap with any other Anypoint VPC’s CIDR Blocks, or any CIDR Blocks in
use in your corporate network.
What is the most performant out-of-the-box solution in Anypoint Platform to track
transaction state in an asynchronously executing long-running process implemented as a
Mule application deployed to multiple CloudHub workers?
A.
Redis distributed cache
B.
java.util.WeakHashMap
C.
Persistent Object Store
D.
File-based storage
Persistent Object Store
Explanation: Correct Answer: Persistent Object Store
*****************************************
>> Redis distributed cache is performant but NOT out-of-the-box solution in Anypoint
Platform
>> File-storage is neither performant nor out-of-the-box solution in Anypoint Platform
>> java.util.WeakHashMap needs a completely custom implementation of cache from
scratch using Java code and is limited to the JVM where it is running. Which means the
state in the cache is not worker aware when running on multiple workers. This type of
cache is local to the worker. So, this is neither out-of-the-box nor worker-aware among
multiple workers on cloudhub. https://www.baeldung.com/java-weakhashmap
>> Persistent Object Store is an out-of-the-box solution provided by Anypoint Platform
which is performant as well as worker aware among multiple workers running on
CloudHub. https://docs.mulesoft.com/object-store/
So, Persistent Object Store is the right answer.
What is the main change to the IT operating model that MuleSoft recommends to
organizations to improve innovation and clock speed?
A.
Drive consumption as much as production of assets; this enables developers to discover
and reuse assets from other projects and encourages standardization
B.
Expose assets using a Master Data Management (MDM) system; this standardizes
projects and enables developers to quickly discover and reuse assets from other projects
C.
Implement SOA for reusable APIs to focus on production over consumption; this
standardizes on XML and WSDL formats to speed up decision making
D.
Create a lean and agile organization that makes many small decisions everyday; this
speeds up decision making and enables each line of business to take ownership of its
projects
Drive consumption as much as production of assets; this enables developers to discover
and reuse assets from other projects and encourages standardization
Explanation: Explanation
Correct Answer: Drive consumption as much as production of assets; this enables
developers to discover and reuse assets from other projects and encourages
standardization
*****************************************
>> The main motto of the new IT Operating Model that MuleSoft recommends and made
popular is to change the way that they are delivered from a production model to a
production + consumption model, which is done through an API strategy called API-led
connectivity.
>> The assets built should also be discoverable and self-serveable for reusablity across
LOBs and organization.
>> MuleSoft's IT operating model does not talk about SDLC model (Agile/ Lean etc) or
MDM at all. So, options suggesting these are not valid.
References:
https://blogs.mulesoft.com/biz/connectivity/what-is-a-center-for-enablement-c4e/
https://www.mulesoft.com/resources/api/secret-to-managing-it-projects
| Page 5 out of 16 Pages |
| Previous |
Copyright © - All Rights Reserved